本文档介绍如何在 VS Code 中配置 Ascend C 开发环境的代码提示工具,以提供代码补全和智能提示。
工具下载安装
首先需要安装 VS Code 扩展商店中的 Dev Containers 插件,用于在容器化环境中进行开发。需要先通过 Remote - SSH 插件连接到目标服务器,然后在服务器上安装并使用 Dev Containers 插件。
现在进入容器环境内。在 VS Code 连接到容器的前提下,选择扩展商店中的 clangd 插件,为容器安装。该插件用于提供 C/C++ 代码的智能补全和语义分析。
此插件额外要求下载 clangd 本体:推荐下载 GitHub 上的最新 release,例如对于 x86_64 Linux 系统,可以选择 clangd-linux-21.1.0.zip。
推荐直接使用 wget 命令下载到服务器上的 /export/home/用户名/ 目录下,然后使用 unzip 解压,得到 /export/home/用户名/clangd-linux-21.1.0/ 目录。
接下来需要配置让插件使用该 clangd 可执行文件。推荐只为该容器远程环境修改配置,而不是全局修改 VS Code 的设置(会影响到其他环境乃至账号同步的设置)。具体来说,可以在容器远程环境中打开 VS Code 的设置,然后选择 远程 [容器 xxxx] 标签页,搜索 clangd,找到 Clangd: Path 选项,将其设置为刚才解压得到的 clangd 可执行文件的路径,例如 /export/home/用户名/clangd-linux-21.1.0/bin/clangd。
此时基本配置已经完成。clangd 插件和微软官方的 C/C++ 插件可能会有冲突,建议禁用微软官方的 C/C++ 插件。
host 侧代码补全配置
clangd 的一些好处:
- 代码补全
- 变量类型/参数名提示
- 未使用变量提示
- ……
示意:
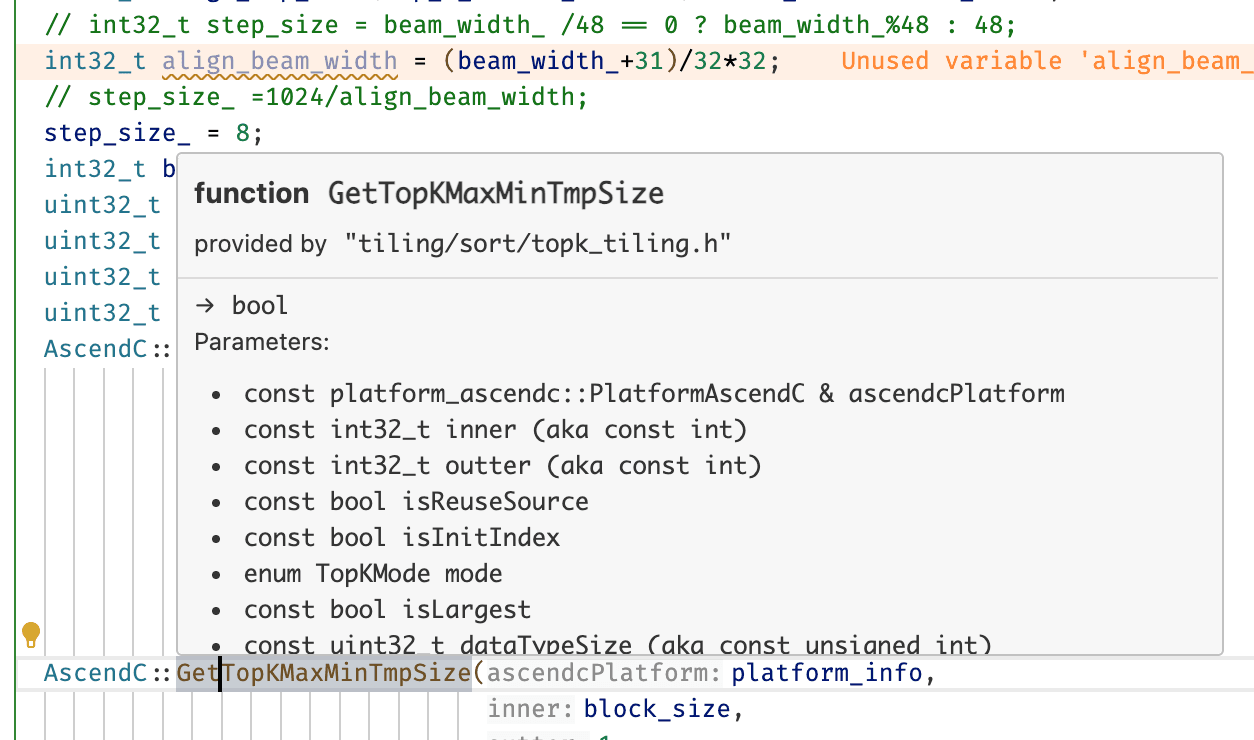
clangd 可以自动识别 CMake 项目,并根据 CMakeLists.txt 文件生成的编译数据库(build/compile_commands.json)提供代码补全和语义分析。我们只需要指示 CMake 生成该编译数据库即可。
推荐直接修改容器的 ~/.bashrc 文件,添加如下内容:
export CMAKE_EXPORT_COMPILE_COMMANDS=1如果想避免每次新创建容器都需要修改 ~/.bashrc,也可以修改创建容器的脚本,在其中增加一个 ~/.bashrc 的映射,或者在创建容器的脚本最后追加:
docker exec -it <container_name_or_id> bash -c 'echo "export CMAKE_EXPORT_COMPILE_COMMANDS=1" >> /root/.bashrc'此时,对于对应的项目,只需要重新运行 CMake 生成编译文件即可:
# rm -rf build
bash ./build.sh # 对应项目的构建脚本应该就会在 build 目录下生成 compile_commands.json 文件,clangd 插件会自动识别。
此外,由于容器环境的问题,部分标准库识别会有问题,需要手动告诉 clangd,可以在 /export/home/用户名/ 目录下创建一个 .clangd 文件,内容如下:
CompileFlags:
Add:
- "--include-directory=/usr/include/c++/12/x86_64-openEuler-linux"
- "--include-directory=/usr/include/c++/12"这里选择的目录 /export/home/用户名/ 并没有什么必要性。clangd 搜索 .clangd 文件时会从当前文件目录开始向上搜索直到根目录,所以放在用户主目录下可以保证所有项目都能找到该配置文件。
device 侧代码补全配置
示意:
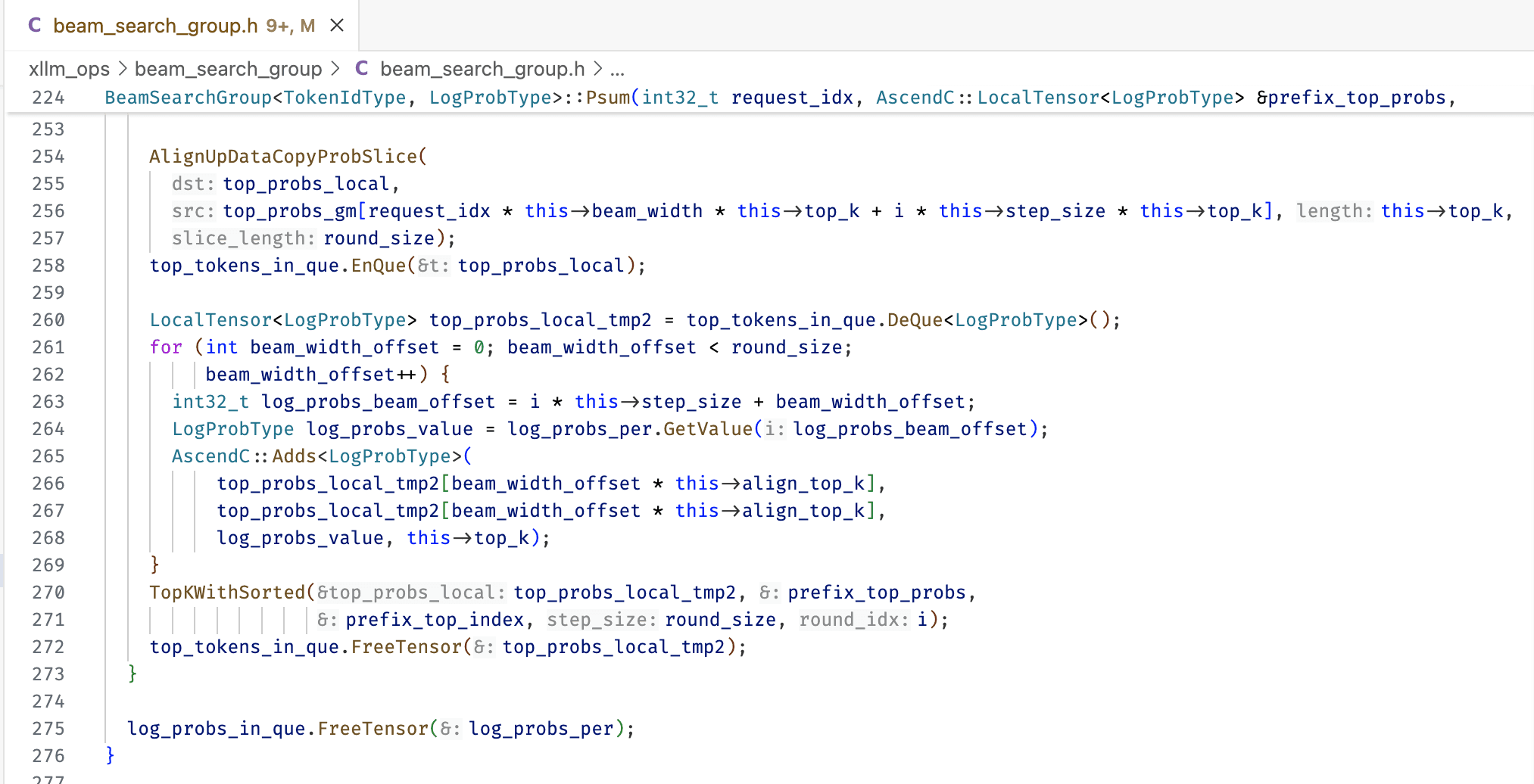
device 侧使用的是 bisheng 编译工具链,clangd 无法自动识别。而且 AscendC 对 C++ 有一定修改,头文件也不能正确自动识别。因此需要手动创建一个 stub.h 头文件,用于提供补全需要的声明。该文件不会在编译时被实际引入。
该文件可以让 AI 代写。可以每次使用到新的 Ascend C API 时,先让 AI 生成该 API 的声明,然后追加到
stub.h文件中。
一个示例 stub.h 将会在最后被给出。为了应用它,我们还需要修改 .clangd 文件,修改为如下内容:
CompileFlags:
Add:
- "--include-directory=/usr/include/c++/12/x86_64-openEuler-linux"
- "--include-directory=/usr/include/c++/12"
# 这里是实际 stub.h 文件所在**目录**(而非文件本身)
- -I/export/home/xxxxxx
- -DUSE_STUB
# 下面是可选的其他配置
- -Wall
- -Wextra
- -Wno-unknown-attributes
- -Wno-unused-parameter然后,对于想要开启代码提示的 device 代码,我们需要手动在开头增加:
#if defined(USE_STUB)
// 这里是 stub 代码
#include "stub.h"
#else
// 这里是实际编译时需要 include 的,例如:
#include "kernel_operator.h"
#include "kernel_tiling/kernel_tiling.h"
#endif这样就可以提示了。
一个示例 stub.h 文件内容如下:
#pragma once
// AscendC 简易 stub,仅用于 IDE/clangd 语义解析与补全。
// 不涉及真实设备、同步
#include <cstdint>
#include <cstddef>
#include <cmath>
#include <cstring>
#define __aicore__
#define __gm__
#define GM_ADDR uint8_t*
#define block_idx 0
namespace AscendC {
// ---------------- 基础枚举/结构 ----------------
enum class QuePosition { VECIN, VECOUT };
enum class TPosition { VECCALC };
enum class HardEvent { V_MTE2 };
enum class RoundMode { CAST_RINT, CAST_FLOOR };
enum class TopKMode { TOPK_NORMAL };
struct DataCopyExtParams {
uint32_t blockLen;
uint32_t blockCount;
uint32_t srcStride;
uint32_t dstStride;
uint32_t rsv;
};
template<typename T>
struct DataCopyPadExtParams {
bool isPad;
T paddingValue;
uint32_t leftPadding;
uint32_t rightPadding;
};
struct TopKInfo {
int32_t outter;
int32_t inner;
int32_t n;
};
// 占位:真实库里包含复杂的 tiling 信息
struct TopkTiling {
int dummy;
};
// ---------------- Tensor 封装 ----------------
template<typename T>
class GlobalTensor {
public:
GlobalTensor();
explicit GlobalTensor(T* p);
void SetGlobalBuffer(T* p);
void SetGlobalBuffer(T* p, size_t offset);
T GetValue(size_t i) const;
void SetValue(size_t i, const T& v);
// 下标返回偏移后的新的 GlobalTensor
GlobalTensor operator[](size_t offset) const;
T* raw() const;
private:
T* ptr_;
};
template<typename T>
class LocalTensor {
public:
LocalTensor();
LocalTensor(T* p, size_t sz);
T GetValue(size_t i) const;
void SetValue(size_t i, const T& v);
size_t Size() const;
T* raw() const;
// 产生从偏移开始的视图(不改变底层所有权)
LocalTensor operator[](size_t offset) const;
private:
T* ptr_;
uint32_t size_;
};
class TPipe {
public:
template<typename Q>
void InitBuffer(Q&, int slots, size_t bytes);
template <typename Q>
void InitBuffer(Q&, size_t bytes);
int FetchEventID(HardEvent);
};
template<QuePosition P, int Depth>
class TQue {
public:
TQue();
void InitBuffer(int slots, size_t bytes);
template<typename T>
LocalTensor<T> AllocTensor();
template<typename T>
void EnQue(LocalTensor<T>& t);
template<typename T>
LocalTensor<T> DeQue();
template<typename T>
void FreeTensor(LocalTensor<T>&);
};
template<TPosition P>
class TBuf {
public:
TBuf();
void InitBuffer(size_t bytes);
template<typename T>
LocalTensor<T> Get();
template<typename T>
LocalTensor<T> GetWithOffset(size_t totalAligned, size_t byteOffset);
};
// ---------------- 常用算子 stub 声明 ----------------
template<typename T>
void Duplicate(LocalTensor<T> dst, T value, int32_t count);
template<typename T>
void DataCopy(LocalTensor<T> dst, LocalTensor<T> src, int32_t count);
template<typename T>
void DataCopy(GlobalTensor<T> dst, LocalTensor<T> src, int32_t count);
template<typename T>
void DataCopy(LocalTensor<T> dst, GlobalTensor<T> src, int32_t count);
template<typename T>
void DataCopyPad(LocalTensor<T> dst, GlobalTensor<T> src, const DataCopyExtParams& cp);
template<typename T>
void DataCopyPad(LocalTensor<T> dst, GlobalTensor<T> src,
const DataCopyExtParams& cp,
const DataCopyPadExtParams<T>& pad);
template<typename T>
void Adds(LocalTensor<T> dst, LocalTensor<T> src, T scalar, int32_t count);
template<typename T>
void Adds(GlobalTensor<T> dst, LocalTensor<T> src, T scalar, int32_t count);
template<typename T>
void Sub(LocalTensor<T> dst, LocalTensor<T> a, LocalTensor<T> b, int32_t count);
template<typename T>
void Mul(LocalTensor<T> dst, LocalTensor<T> a, LocalTensor<T> b, int32_t count);
template<typename T>
void Div(LocalTensor<T> dst, LocalTensor<T> a, LocalTensor<T> b, int32_t count);
// 四舍五入/向下取整函数声明
float round_rint(float v);
float round_floor(float v);
template<typename DstT, typename SrcT>
void Cast(LocalTensor<DstT> dst, LocalTensor<SrcT> src, RoundMode mode, int32_t count);
// ---------------- 事件 / 同步 ----------------
// 非模板版本(按需可用)
void SetFlag(HardEvent);
void WaitFlag(HardEvent);
// 模板版本以支持如下调用:SetFlag<HardEvent::V_MTE2>(eventId);
template<HardEvent E>
void SetFlag(int eventId);
template<HardEvent E>
void WaitFlag(int eventId);
// 管道栅栏
#define PIPE_MTE2 1
template<int PIPE>
void PipeBarrier();
// ---------------- TopK 声明 ----------------
template<typename T, bool NeedIndex, bool Sorted, bool Dummy, TopKMode Mode>
void TopK(LocalTensor<T> dst_values,
LocalTensor<int32_t> dst_indices,
LocalTensor<T> src_values,
LocalTensor<int32_t>& src_idx,
LocalTensor<bool>& src_finish,
LocalTensor<uint8_t>& tmp,
int32_t k,
TopkTiling& tiling,
TopKInfo& info,
bool isLargest);
// ---------------- 其他辅助 ----------------
template<typename T>
void Adds(GlobalTensor<T> dst, GlobalTensor<T> src, T scalar, int32_t count);
} // namespace AscendC